文章地址: U-Net: Convolutional Networks for Biomedical Image Segmentation | SpringerLink
摘要 Abstract
提出了一种网络和训练策略,该策略依赖于大量使用数据增强来更有效地使用可用的标注样本。对训练的样本进行增强
该体系结构由捕获上下文的收缩路径和支持精确本地化的对称扩展路径组成。此外,网络速度很快。在最新的GPU上,分割512x512图像只需不到一秒的时间。
code:U-Net
介绍 Introduction
深度学习在参数和数据集大小上有一些限制,那么对于小样本的学习,就存在一些问题。
卷积网络的应用是在图像分类方面,但在生物医学图像处理方面,往往需要输出定位,对像素的类别标签,如果只有几k的图像,达不到训练的要求。
之后就出现了使用滑动窗口的形式去预测pixel的标签。滑动窗口也是一种数据增强的方式。数据可以大于训练的图像。sliding-window
缺点是对于补丁大小方面存在权衡。
材料和方法 Materials and Methods
该体系结构进行了修改和扩展,使其能够处理非常少的训练图像,并产生更精确的分割
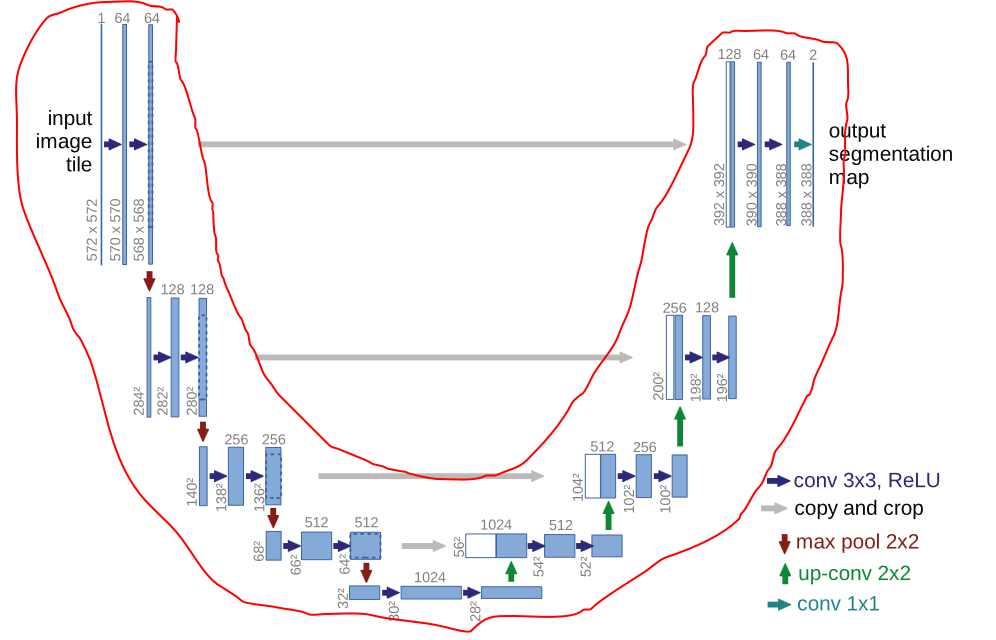
所以叫U-Net
主要是通过连续的层补充收缩网络,池操作符用上采样操作符来代替。因此,这些层提高了输出的分辨率。为了定位,将收缩路径的高分辨率特征与上采样输出相结合。然后,连续的卷积层可以学习基于该信息组合更精确的输出。
如果将左边视作为编码,将右边视作为解码
同层编码也会输出到同层的解码,有种残差的味道
不存在全连接层。即仅存在卷积的操作。
input: 572x572(通过镜像处理过的图片)
op: 64x570x570 64个可学习的卷积核
op: 64x568x568 64个可学习的卷积核
op: 284x284 2x2池化
...
op: 32x32 2x2池化
...
op: 28x28 2x2池化
op: 1024x56x56 同层的512x64x64与512x56x56想结合并裁剪多余部分
...
通过对可用的训练图像应用弹性变形来进行过度的数据增强。
模型近可能的去模拟生物领域组织的真实变形。
对于原始图片是512x512的尺寸,U-Net使用Overlay-tile Strategy对边缘进行非0填充。
Overlay-tile Strategy的目的是对更大的图做分割时可以无缝拼接?
572可以是的每次进行降采样后的尺寸都是偶数。
U-Net的损失函数是使用加权损失,其中接触单元之间分离的背景标签在损失函数中获得较大的权重。
能量函数通过pixel的softmax的交叉熵loss function计算。
$E=\sum_{\mathbf{x}\in\Omega}w(\mathbf{x})\mathrm{log}(p_{\ell(\mathbf{x})}(\mathbf{x}))$
$K$ is the number of classes and $p_k(x)$ is the approximated maximum-function.
每个类别的最大值函数与标签进行交叉熵。$w(x)$是权重,重点关注某些像素。
使用SGD方法
使用形态学运算计算分离边界。然后,权重图计算为:
$$
w(\mathbf{x})=w_c(\mathbf{x})+w_0\cdot\exp\left(-\frac{(d_1(\mathbf{x})+d_2(\mathbf{x}))^2}{2\sigma^2}\right)
$$
这里 $w_c:\Omega\in\mathbb{R}$ 是平衡类别比例的权值,$d_1:\Omega\in\mathbb{R}$ 是像素点到距离其最近的细胞的距离, $d_2:\Omega\in\mathbb{R}$ 则是像素点到距离其第二近的细胞的距离。$w_0$ 和 $\sigma$ 是常数值,在实验中 $w_0=10$
, $\sigma\approx5:。$ why?
文中对于模型描述的原话:
The network architecture is illustrated in Figure 1. It consists of a contracting path (left side) and an expansive path (right side). The contracting path follows the typical architecture of a convolutional network. It consists of the repeated application of two 3x3 convolutions (unpadded convolutions), each followed by a rectified linear unit (ReLU) and a 2x2 max pooling operation with stride 2 for downsampling. At each downsampling step we double the number of feature channels. Every step in the expansive path consists of an upsampling of the feature map followed by a 2x2 convolution (“up-convolution”) that halves the number of feature channels, a concatenation with the correspondingly cropped feature map from the contracting path, and two 3x3 convolutions, each followed by a ReLU. The cropping is necessary due to the loss of border pixels in every convolution. At the final layer a 1x1 convolution is used to map each 64-component feature vector to the desired number of classes. In total the network has 23 convolutional layers. To allow a seamless tiling of the output segmentation map (see Figure 2), it is important to select the input tile size such that all 2x2 max-pooling operations are applied to a layer with an even x- and y-size.
比如这是二分类,输入两个维度表示每个类别的情况。
文中使用随机位移向量在粗略的3x3网格上生成平滑变形。
结果 Result
U-Net在医学图像分割方面效果很好。
总结 Conclusion
U-Net是比较早的使用多尺度特征进行语义分割任务的算法之一,其U形结构也启发了后面很多算法。但其也有几个缺点:
有效卷积增加了模型设计的难度和普适性;目前很多算法直接采用了same卷积,这样也可以免去Feature Map合并之前的裁边操作
其通过裁边的形式和Feature Map并不是对称的,个人感觉采用双线性插值的效果应该会更好。
问题 Question
ISBI细胞跟踪挑战赛?
Overlay-tile Strategy?
EM stacks?